# PostgreSQL 命令
# 命令
# 数据库操作
# 创建数据库
CREATE DATABASE dbname;
# 列举数据库
查看已经存在的数据库
\l
# 选择数据库
\c + dbname
# 删除数据库
DROP DATABASE dbname;\d
DROP DATABASE IF EXISTS dbname;
查看已经存在的表格
\d
查看指定表格信息
\d tablename
删除表格
DROP TABLE table_name;
# 表格操作
# 创建表格
CREATE TABLE table_name
eg:
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL,
JOIN_DATE DATE
);
# 列举表格
\d
# 选择表格
\d table_name
# 删除表格
DROP TABLE table_name;
# Schema操作
# 创建Schema
CREATE SCHEMA schema_name;
eg:
create table yixing.company(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25),
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID)
);
# 删除Schema
DROP SCHEMA schema_name;
删除一个模式以及其中包含的所有对象:
DROP SCHEMA schema_name CASCADE;
# SQL
# INSERT 插入
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN)
VALUES (value1, value2, value3,...valueN);
eg:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (1, 'Paul', 32, 'California', 20000.00,'2001-07-13');
# SELECT 选择
选择具体的某列
SELECT column1, column2,...columnN FROM table_name;
选择所有列
SELECT * FROM table_name;
eg:
SELECT ID,NAME FROM company;
SELECT * FROM company;
# WHERE/AND/OR/IN/BETWEEN 条件
SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
SELECT * FROM COMPANY WHERE AGE IS NOT NULL;
SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
子查询
SELECT AGE FROM COMPANY WHERE EXISTS (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
# UPDATE 更新
规则:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
示例:
UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
# DELETE 删除
规则:
DELETE FROM table_name WHERE [condition];
示例:
DELETE FROM COMPANY WHERE ID = 2;
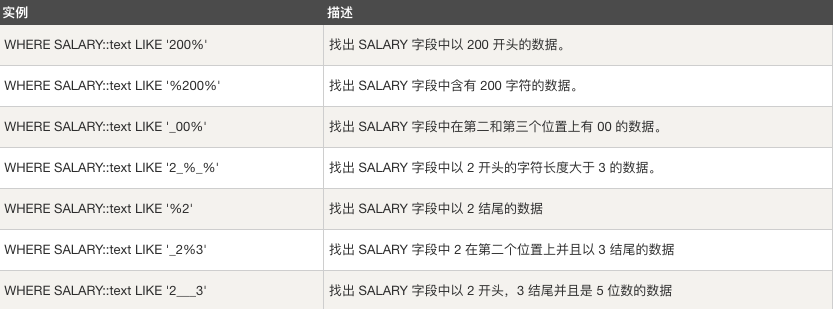
# LIKE 子句
在 LIKE 子句中,通常与通配符结合使用,通配符表示任意字符,在 PostgreSQL 中,主要有以下两种通配符:
- 百分号 %
- 下划线 _
如果没有使用以上两种通配符,LIKE 子句和等号 = 得到的结果是一样的。
规则
SELECT FROM table_name WHERE column LIKE 'XXXX%';
或者
SELECT FROM table_name WHERE column LIKE '%XXXX%';
或者
SELECT FROM table_name WHERE column LIKE 'XXXX_';
或者
SELECT FROM table_name WHERE column LIKE '_XXXX';
或者
SELECT FROM table_name WHERE column LIKE '_XXXX_';
示例:
# LIMIT
规则:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows]
示例:
SELECT * FROM COMPANY LIMIT 4;
SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
# ORDER BY
在 PostgreSQL 中,ORDER BY 用于对一列或者多列数据进行升序(ASC)或者降序(DESC)排列
规则:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
示例:
SELECT * FROM COMPANY ORDER BY AGE ASC;
SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;
# GROUP BY
在 PostgreSQL 中,GROUP BY 语句和 SELECT 语句一起使用,用来对相同的数据进行分组。GROUP BY 在一个 SELECT 语句中,放在 WHERE 子句的后面,ORDER BY 子句的前面。
规则:
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
GROUP BY 子句必须放在 WHERE 子句中的条件之后,必须放在 ORDER BY 子句之前。
在 GROUP BY 子句中,你可以对一列或者多列进行分组,但是被分组的列必须存在于列清单中。
示例:
SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;
# WITH
# HAVING
规则:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
示例:
SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) < 2;
SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) > 1;
# DISTINCT
在 PostgreSQL 中,DISTINCT 关键字与 SELECT 语句一起使用,用于去除重复记录,只获取唯一的记录。我们平时在操作数据时,有可能出现一种情况,在一个表中有多个重复的记录,当提取这样的记录时,DISTINCT 关键字就显得特别有意义,它只获取唯一一次记录,而不是获取重复记录。
规则:
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
示例:
SELECT DISTINCT name FROM COMPANY;
# 运算符
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号。PostgreSQL 运算符是一个保留关键字或字符,一般用在 WHERE 语句中,作为过滤条件。常见的运算符有:
- 算术运算符
- 比较运算符
- 逻辑运算符
- 按位运算符
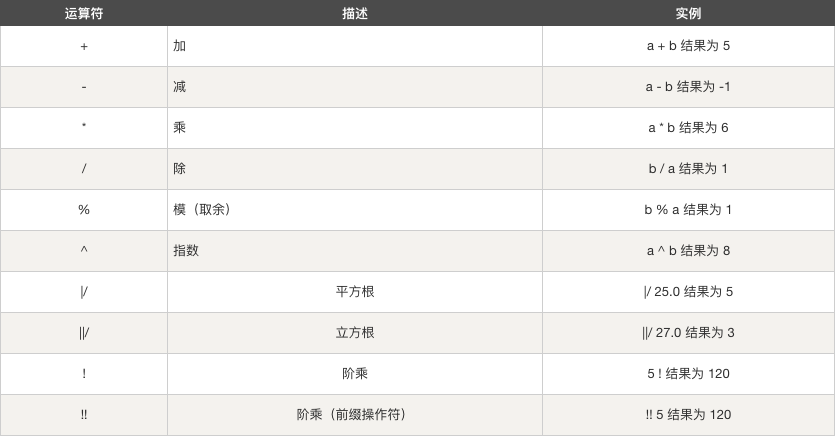
# 算术运算符
假设变量 a 为 2,变量 b 为 3,则:
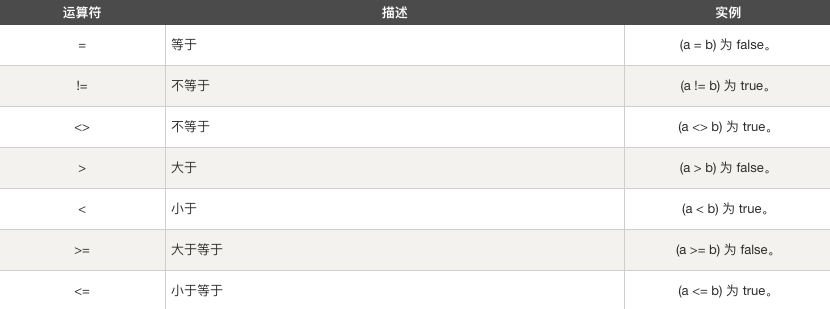
# 比较运算符
假设变量 a 为 10,变量 b 为 20,则:
# 逻辑运算符
PostgreSQL 逻辑运算符有以下几种:
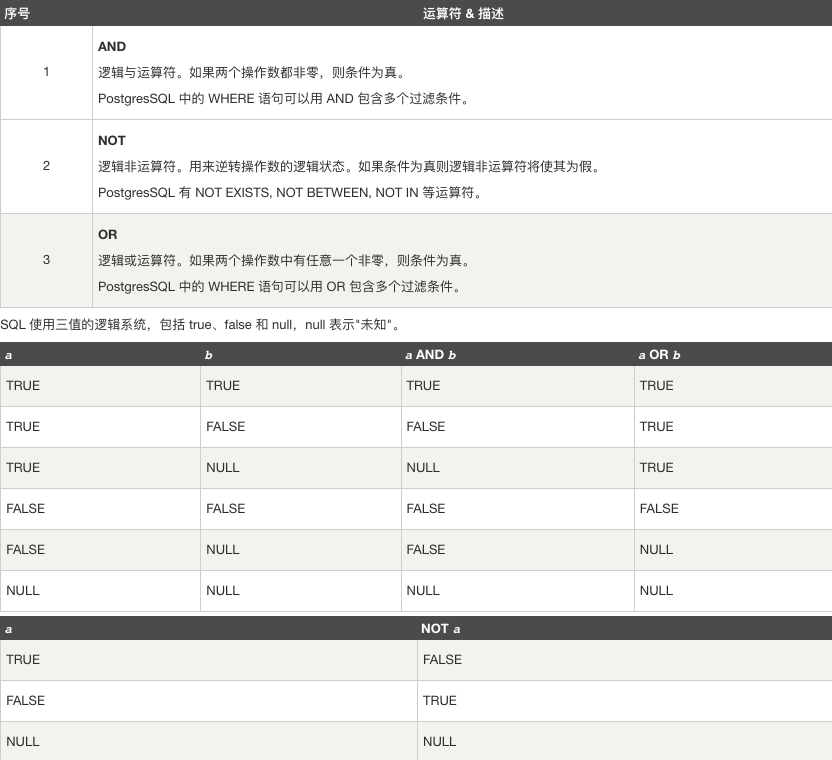
# 按位运算符
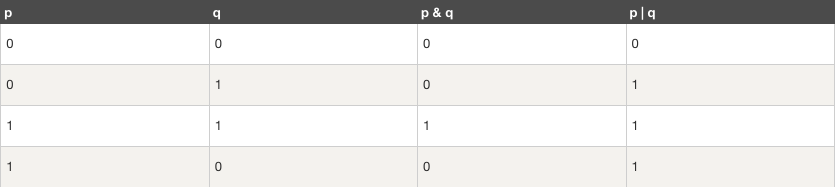
位运算符作用于位,并逐位执行操作。&、 | 和 ^ 的真值表如下所示: